
Introducing smart tags for analyzing video and written feedback

Collecting customer and user feedback has become a cornerstone for building exceptional products and experiences. However, it’s not without its challenges. Methods like usability testing can generate tons of quality insights, but they’re not always easy to parse out. At UserTesting, we believe that all teams should have access to actionable insights that lead to people-centric solutions. Through smart tags, we’ve made it easier to do just that.
What are smart tags?
In a nutshell, smart tags are a great way to quickly review large quantities of feedback. With smart tags, you can see suggestions, expectations, and expressions of sentiment, like confusion or delight, directly within the video player, transcript, or written response.
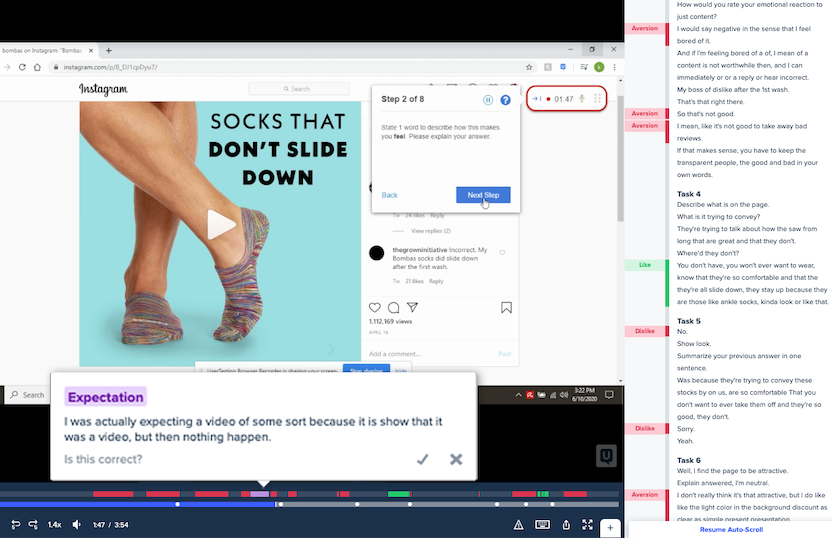
How do smart tags work?
To power this new feature we developed a purpose-built machine learning model to handle our natural language processing (NLP) needs. The goal was to create a model which evaluates feedback in a very human way, based specifically on the types of feedback being collected on our platform.
In this case, we wanted to make sure that our natural language processing approach identified moments that matter specifically for researchers, designers, product managers, or other users of our platform. For this, we used an extremely sophisticated approach called Bidirectional Encoder Representations from Transformers (BERT) which, unlike other NLP techniques, takes into account the context for each occurrence of a given word.
This was crucial for developing the smart tags. If we used models designed to analyze social media posts, earnings calls, transcripts from call centers, or something of the like, the output would likely not provide tags frequently associated with customer experience feedback.
How we chose which smart tags to include
In order to generate smart tags that truly matter to our users, our model was developed by focusing on common observations made by users on our platform. As such, we focused on smart tags that were most often highly correlated to positive, negative, and neutral sentiments:

These labels were selected based on analyzing notes, clips, and highlight reels generated within our platform. We looked for artifacts, evidence, and notes of where our users defined specific areas of interest within videos. We then took those artifacts and clustered them into groups. Some of this was done using machine learning and algorithmic approaches, some were tuned by inferences of internal experts, and all of it was a reflection of the types of tags our customers and internal pros are using already.
Positive smart tags
- Easy: the “easy” label identifies points within a transcript or written response when a positive experience is also characterized by its simplicity. This label has been valuable in differentiating experiences that are easy to accomplish.
- Like: the “like” label replaces “positive” sentiment statements not characterized with the easy label. “Like” can identify positive experiences outside of the user experience testing domains.
Negative smart tags
- Pain point: the “pain point” label identifies statements showing when users struggle to accomplish an intended goal. The “pain point” label is often present with other labels like “confusion” or “aversion”. This label assists in identifying root causes for other negative sentiments.
- Confusion: the “confusion” label identifies when users are confused. This often occurs in conjunction with pain points.
- Aversion: the “aversion” label identifies when users do not like what they are seeing. Normally aversion is associated with designs.
- Dislike: the “dislike” label is applied when the negative sentiment is present and the other negative labels are not applied. Dislike is useful in finding negative sentiments outside of our domain.
Other smart tags
- Expectation: the “expectation” label identifies points within a transcript or written response when a user’s expectations are addressed. This is not necessarily negative because some users identify their expectations as being met. This can be used in conjunction with “suggestion” as often users will make suggestions associated with their missed or met expectations.
- Trust: the “trust” label identifies when users express trust in a company, brand, or experience. This often comes into play when brands are testing messaging, security is in question, or handling of data is the topic of discussion.
- Suggestion: the “suggestion” label identifies when users made suggestions. This is useful to identify recommendations and suggestions by users on how to remedy issues.
- Price: the “price” label identifies when users are talking about the expense or cost of products.
How machine learning models apply smart tags
Once the labels were selected, we had a data set of over ten thousand examples to feed into our machine learning models. We passed in sections of transcripts that customers or internal pros had labeled with smart tags. We were then able to provide all of these historical examples of smart tags to a machine learning model. That model was able to unpack these sentences and understand what makes a sentence indicate like versus dislike, confusion versus trust, or simply identify when someone is discussing price. The more data available, the more nuanced speech patterns the machine learning can pick up.
After the machine learning models are trained, we can pass in any transcript or written response from a study, and the model is able to predict which smart tag, combination of smart tags, or lack of a smart tag is most appropriate. This is real human-level empathy and synthesis passed through a machine learning model. By training the machine learning model in such a way, it’s able to accurately predict which labels a human would likely apply themselves.
A final note on smart tags
Developing smart tags was a collaborative effort between our marketing, product, research, artificial intelligence, and data engineering teams. The awesome thing about working in artificial intelligence, machine learning, or data engineering at UserTesting is that we have treasure troves of anonymized historical data to learn from.
If you’d like to join the teams working on the next level of machine learning and engineering, check out our careers page.
In this Article

April 2021 Product Release
April 2021 Product Release


